Openset in CVPR2019
C2AE: Class Conditioned Auto-Encoder for Open-set Recognition(Oral)【分类识别】
可惜咯没代码
摘要
我们提出了一种openset识别算法,该算法使用具有新颖训练和测试方法的类条件自动编码器class conditioned auto-encoders 。与先前的方法相比,训练过程分为两个子任务
- 闭集分类
- 开集识别(即,将类识别为已知或未知)
编码器学习闭合集分类训练管道之后的第一个任务,而解码器通过重构以类身份为条件来学习第二个任务。此外,我们使用统计建模的极值理论对重建误差进行建模,以找到识别已知/未知类样本的阈值。此外,我们使用统计建模的极值理论来模拟重建误差,以找到识别已知/未知类样本的阈值
- 基于类条件自动编码器的新型训练和测试算法提出了一种新的开放式识别方法。
- 我们表明,在子任务中划分开集问题可以帮助学习更好的开集识别分数。
- 对各种图像分类数据集进行了大量实验,并对几种最新的最新方法进行了比较。此外,我们通过消融实验分析了所提方法的有效性。
方法
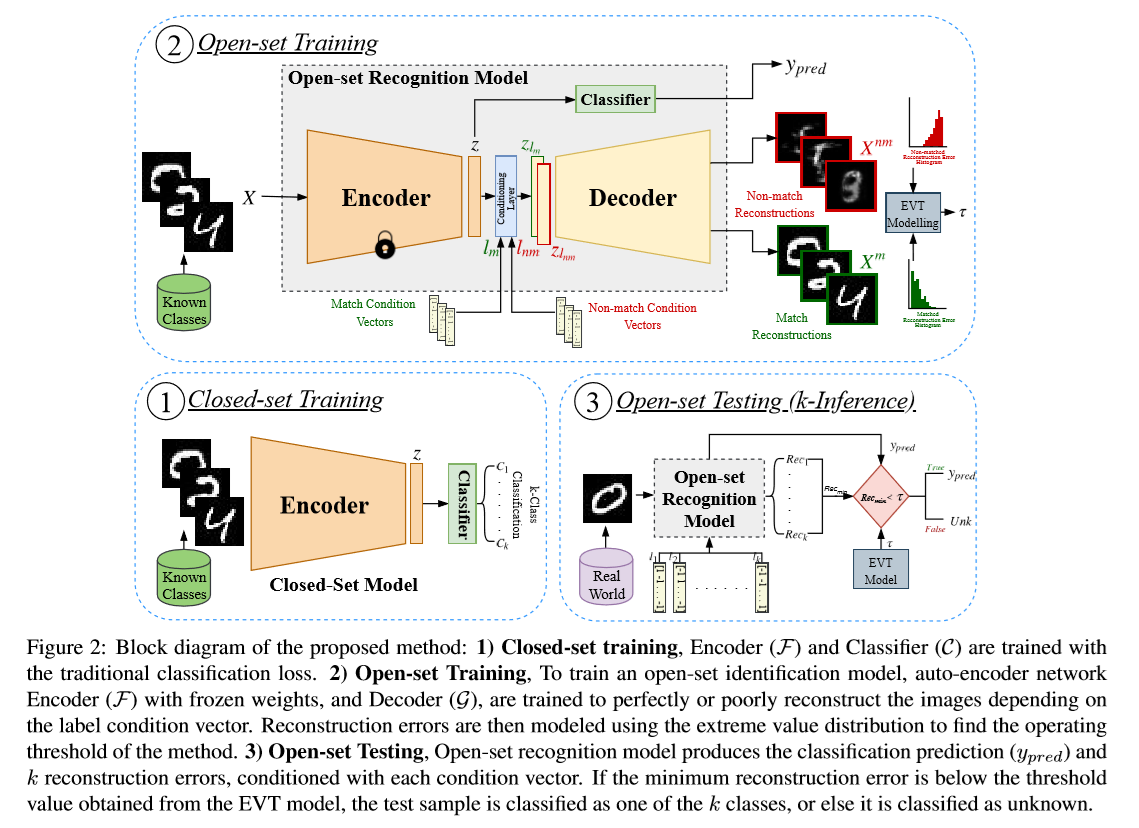
- stage1
Closed-set Training:编码器(F)和分类器(C)参数分别为Θf和Θc,以交叉熵损失进行训练,
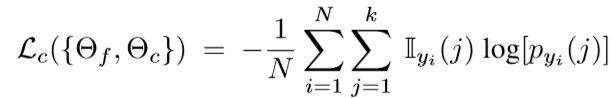
- stage2
Open-set Training:开放式训练中有两个主要部分,即条件解码器训练,然后EVT对重建error的建模。在这个stage,编码器和分类器权重都是固定的,并且不会进行优化。 -
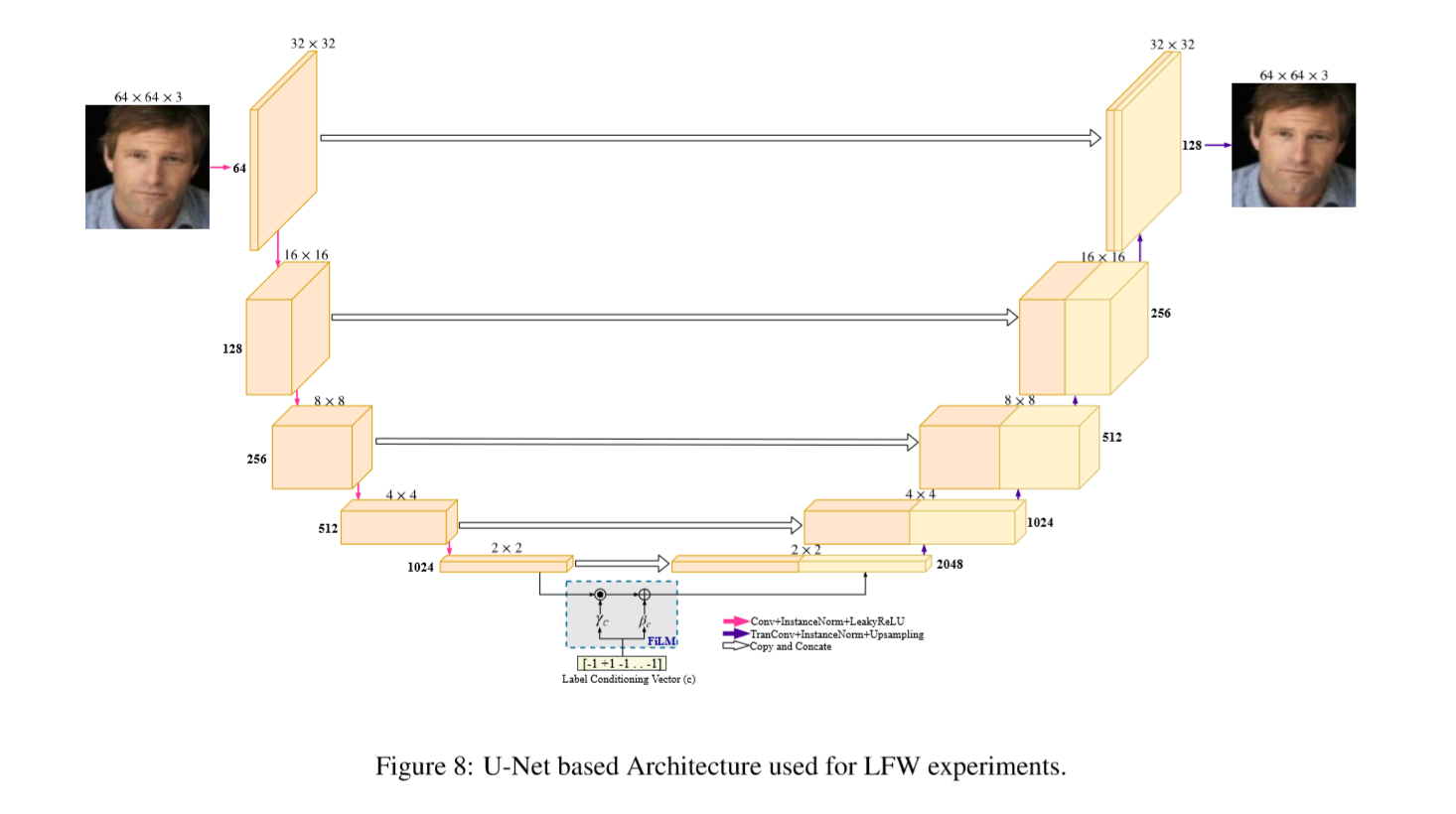
- Conditional Decoder Training :前面经过encoder生成的向量,经过一个FiLM的层,这个层带来的操作就是给出条件信息( conditioning information)。对于输入特征z和包含条件信息的向量lj可以给出
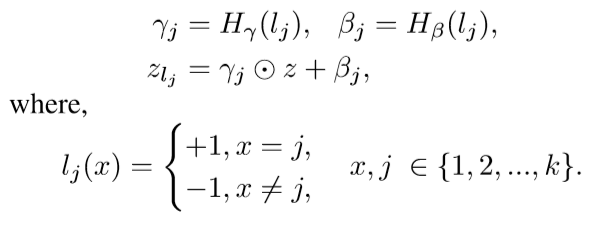 对于解码器G来说,在得到条件信息l之后可以根据下式进行解码
对于解码器G来说,在得到条件信息l之后可以根据下式进行解码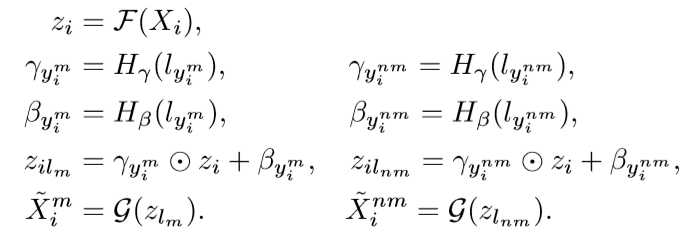 Loss是重建之后的1范式误差
Loss是重建之后的1范式误差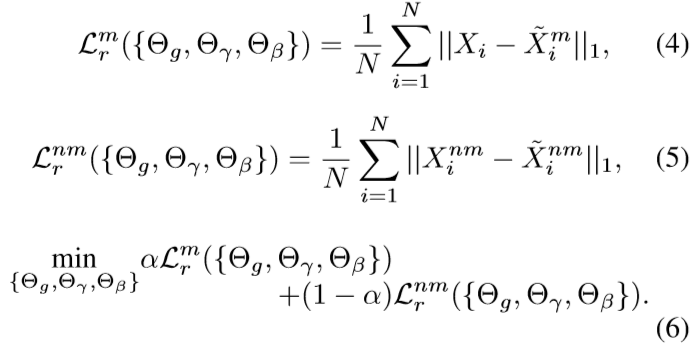
- EVT 模型:使用
MEF(mean excess function)算法找到阈值u,超过u的使用下式GPD估算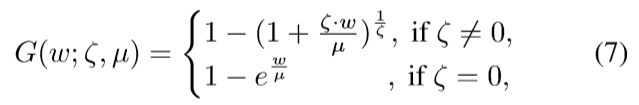 可以使用最大似然估计技术容易地估计ζ和μ
可以使用最大似然估计技术容易地估计ζ和μ - Threshold Calculation:
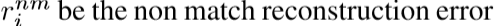
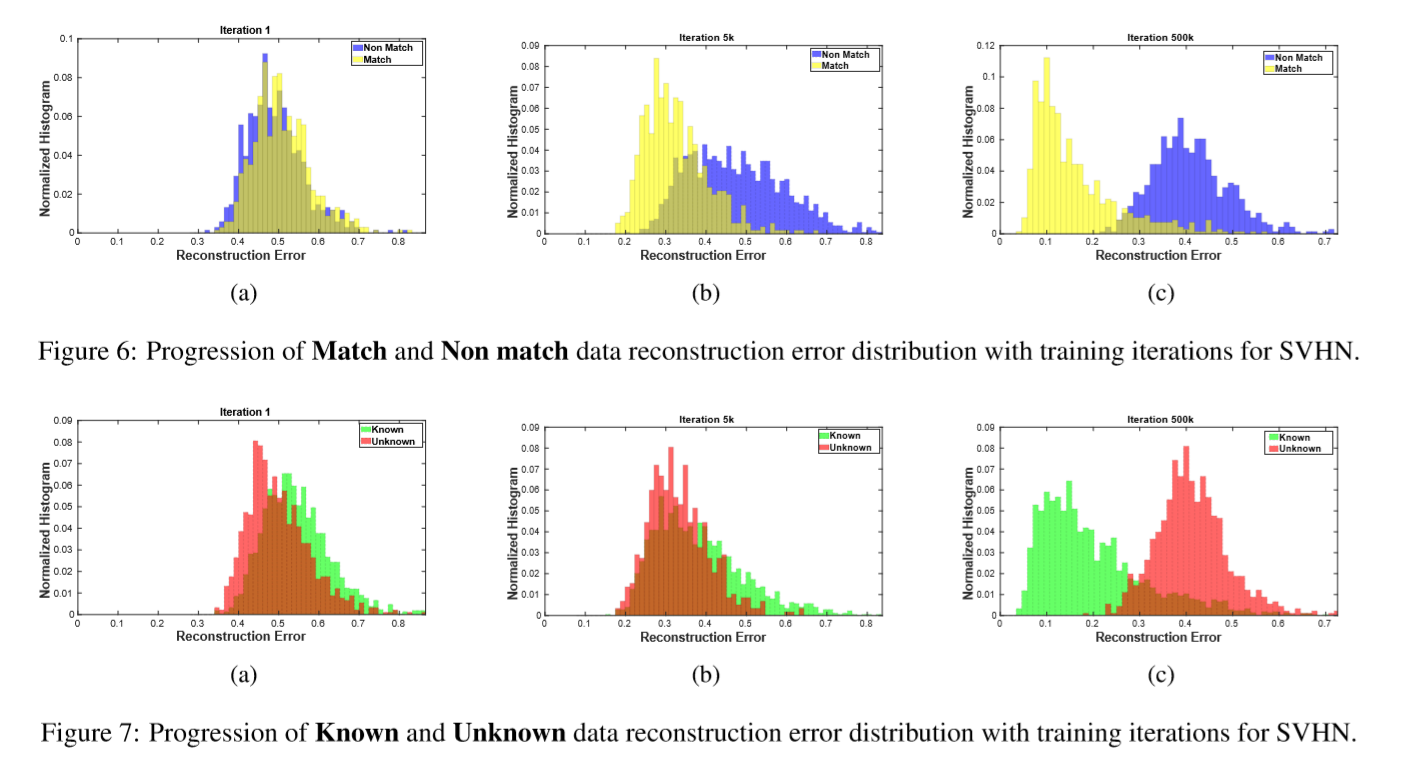
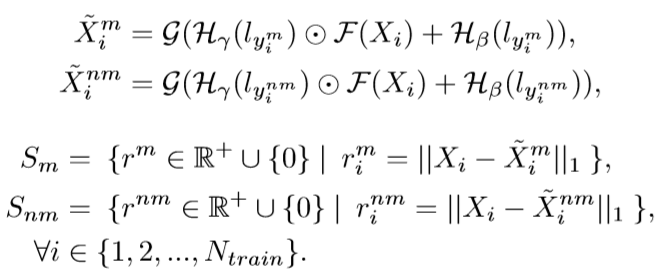 下图当中a表示了匹配和不匹配的重建误差,b是测试阶段的已知和未知的重建误差,很好的近似
下图当中a表示了匹配和不匹配的重建误差,b是测试阶段的已知和未知的重建误差,很好的近似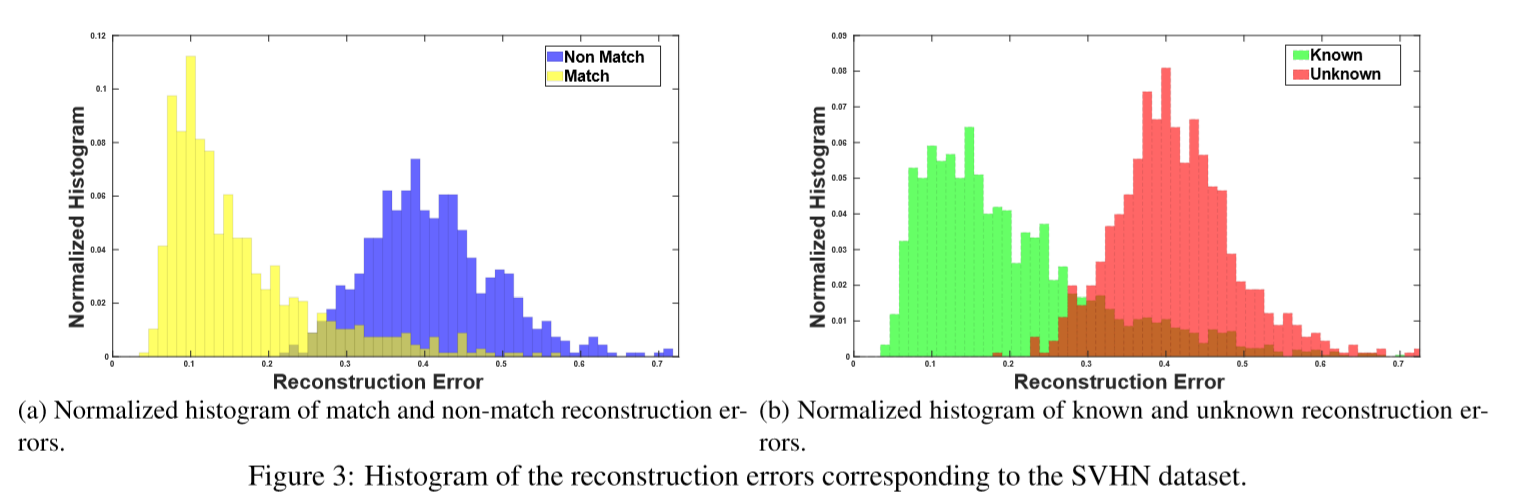 现在要为match和nomatch找一个边界了,最小化下式找到threshold。
现在要为match和nomatch找一个边界了,最小化下式找到threshold。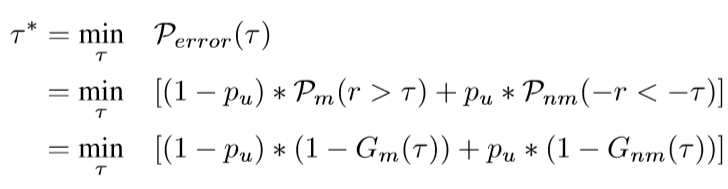 对应图中的交叉最小的部分
对应图中的交叉最小的部分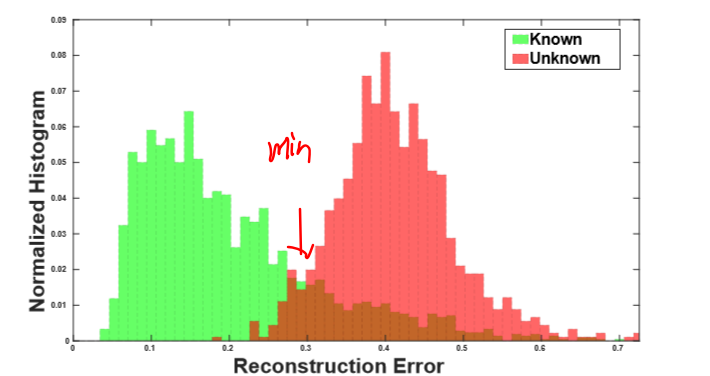
- Conditional Decoder Training :前面经过encoder生成的向量,经过一个FiLM的层,这个层带来的操作就是给出条件信息( conditioning information)。对于输入特征z和包含条件信息的向量lj可以给出
- stage3推断部分k-inference algorithm.

实验
openess定义
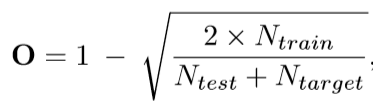
- 实验1:Open-set Identification ROC曲线下面积 改变threshold来得到曲线 ROC就是:
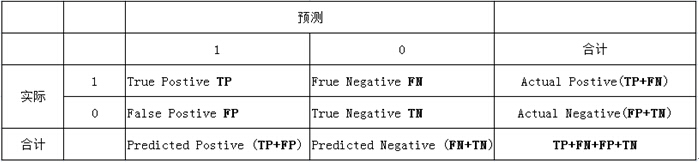
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。Sensitivity
(2)负正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。1-Specificity
(3)真负类率(True Negative Rate)TNR: TN/(FP+TN),代表分类器预测的负类中实际负实例占所有负实例的比例,TNR=1-FPR。Specificiy
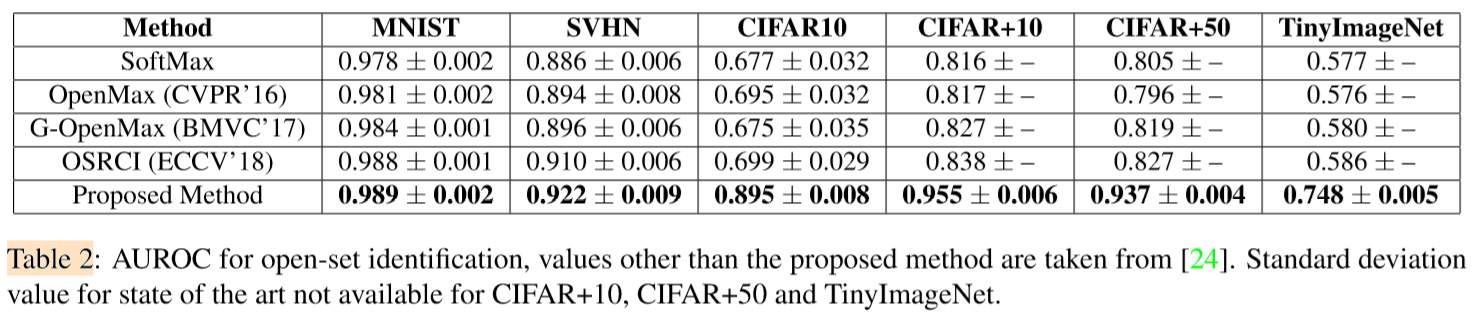
- 实验2:Open-set Recognition
补充资料
训练过程中 分布逐渐分开的过程
基于unet网络的网络结构
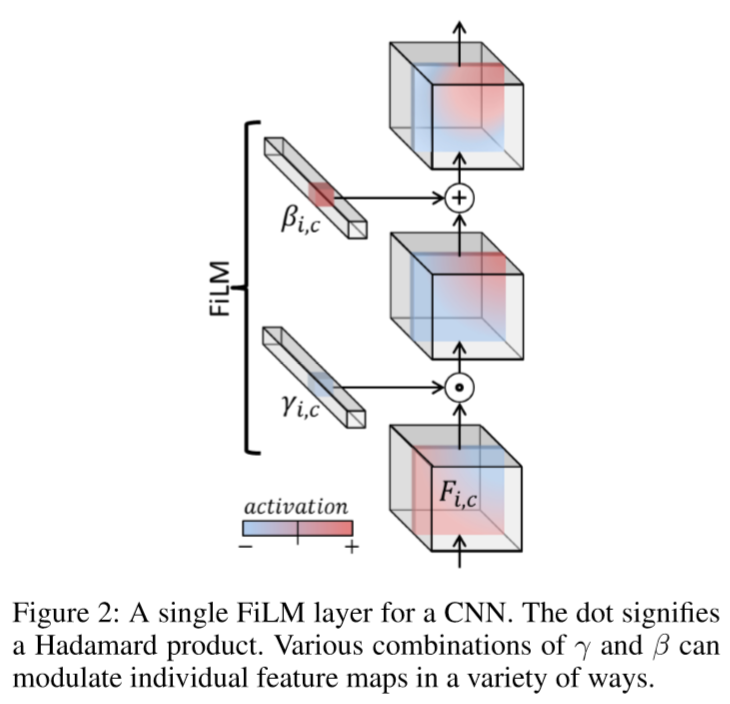
FiLM layer is a conditioning layer which modulates feature maps from C(1024)
with linear modulation parameters γc and βc of size 1024×2×2,
based on label conditioning vector.
FiLM网络结构
Classification-ReconstructionLearningforOpen-SetRecognition
摘要
先是批判了一番现有的openset分类器依赖于以受监督方式训练的深度网络对训练集中的已知类;这导致学习表示对已知类的特化,并且难以区分未知和未知。本文提出了一个新的结构联合了分类和输入数据的重建。这增强了学习的表示,以便保存用于将未知数与知识分离的信息,以及区分已知类别的信息。一个下新的分类-重建学习方法 Classification-Reconstruction learning for Open-Set Recognition(CROSR)利用潜在表示来重建可修复的自我检测,而不会损害已知的分类精度。
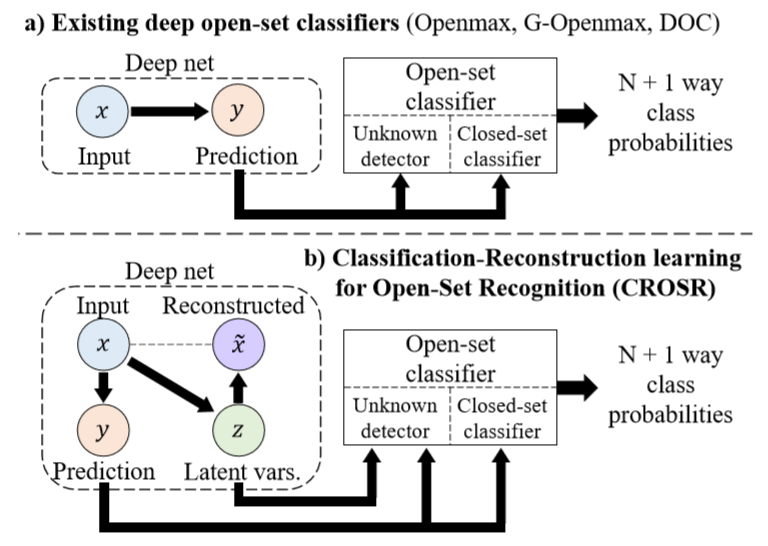
贡献:
- 第一次讨论了在openset中基于深度重建的表征学习的有用性
- 开发了一种新的开放式识别框架CROSR,它基于DHRNets并使用它们联合执行已知的分类和未知检测。
- 在五个标准图像和文本数据集中进行了开集分类的实验,结果表明我们的方法优于已知数据和异常值的大多数组合的现有深度开集分类。
算法说白了就是用每个Zl替代AV
本算法基于openmax
weibull分布模拟EVT模型
distance使用的是l2距离
| 问题在于:AV不一定是用于对类属性p(x∈Ci)建模的最佳表示。虽然监督网络中的AV被优化以给出正确的p(Ci | x),但是不鼓励它们编码关于x的信息,并且仅测试x本身是否可能在Ci中是不够的。 |
加入了一个解码器,让隐藏向量更有意义
距离函数改为,[y,z]表示y和z的矢量的连接,μi表示它们在类Ci中的平均值。
- Deep Hierarchical Reconstruction Nets (DHRNets)
每层的传播细节为:
我们将来自已知类的训练数据中的分类错误和重建错误的总和最小化。为了测量分类误差,我们使用y和标签的softmax交叉熵。为了测量x和x~的重建误差,我们使用图像中的l2距离和文本中单热词表示的交叉熵。
请注意,我们不能在训练中使用未知类的数据,并且仅使用已知样本计算重建损失。整个网络可以使用基于梯度的方法进行区分和训练。在训练网络并确定其权重后,我们计算未知检测的Weibull分布。
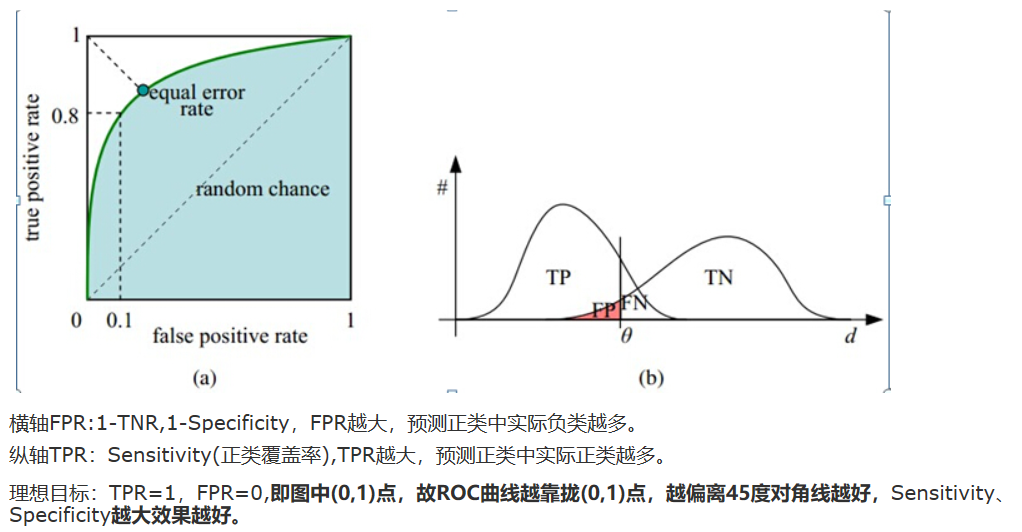
实验 实验部分只跟softmax和openmax比较 在各个数据集上情况如下
- minist
- Cifar10
About plain CNN and DenseNet:
Densenet is state-of-the-art network for closed-set image classification.
The plain CNN is a VGGNet-style network re-designed for CIFAR, and it has 13 layers.
图形化结果,能看到用文中方法聚合更正确更紧凑
Weakly Supervised Open-set Domain Adaptation by Dual-domain Collaboration
weakly supervised + open-set + domain adaptation, 到底想干嘛
摘要 出现了一个新的问题
在传统的域适应中,关键的假设是存在完全标记的域(源),其包含与另一个未标记或几乎不标记的域(靶)相同的标记空间。但是,在现实世界中,经常存在应用场景,其中两个域都被部分标记,并且并非所有类都在这两个域之间共享。因此,让部分标记的域相互学习以在开放设置下对每个域中的所有未标记样本进行分类是有意义的。
第一次在Open set domain adaptation(ICCV2017).
通过weakly supervised open-set domain adaptatio 考虑openset问题。提出了协同分配协调Collaborative Distribution Alignment(CDA)方法,该方法双边进行知识转移,并协同工作以对未标记数据进行分类并识别异常值样本。
应用场景:两队人带着数据集一起做 大家都只标注了一部分数据集,然后大家一起混着用。
关键就是把两个域的数据投影到一个公共空间,同时为了解决openset问题,投影的时候要让已知的和未知的距离足够大。具体做法如图:
- 来自不同类别的标记样本用相应的颜色填充,而灰色样本未标记。每个样本的形状表明其真实性。具体而言,菱形样品代表未知类样品。请注意,未知类样本是无法在已知标签空间中表示的样本,而未标记样本是没有标签信息的样本。因此,未知类样本可以是标记的或未标记。
- 我们为一些未标记的样本分配伪标签(由外框颜色表示),同时将剩余的不确定样本排除为异常值。
- 我们学习了一组特定于域的映射,这些映射将样本转换到潜在域,同类样本被聚合,并且形成未知和已知类样本之间的分离。然后,我们使用变换后的特征来更新(b)中的伪标签,并在(b)和(c)之间迭代直到收敛。
- 在(d)所示的潜在空间中,我们使用基础分类器来注释所有未标记的样本,我们希望将其预测为已知类别之一(红色,绿色和蓝色),或者作为未知类别 - 班级样本(黄色)
算法细节
- 伪标签标注
用已有的方法给unlabel的数据标label。利用信息熵H来估计每个样本的预测的确定性。较高的H意味着概率分布更稀疏,表明该预测更可能是错误的。
,大于阈值的时候就是outlier
-
Dual Mapping Under Open-set Condition 这一步是想让两个域学习到一个潜在空间里面,以往的都是一个往另一个学。有一个问题是分开已知和未知的类别,方法就是使已知类别尽可能地向中心缩小,Loss为
其中fu为离x最近的未标记样本xu的距离,fc为x和样本中心xc的距离
通过最小化DistM和DistC,DA和DB中已知类样本的边际分布和条件分布之间的差异减小,而未知类样本将不会不正确地对齐。
-
Aggregating Same-class Samples 经过上述两种方法之后,将所有样本明确地汇总到他们的类别中心,
-
Objective Function
总loss为
实验
-
office dataset
-
reid数据集
-
Abaltion study