Unsupervised Method in davis2016
Learning to Segment Moving Objects
我们将此作为学习问题制定并用三个线索设计我们的框架:
- 一对帧之间的独立对象运动,其补充对象识别,
- 对象外观,其有助于校正运动估计中的错误
- 时间一致性,这对分割施加了额外的约束。
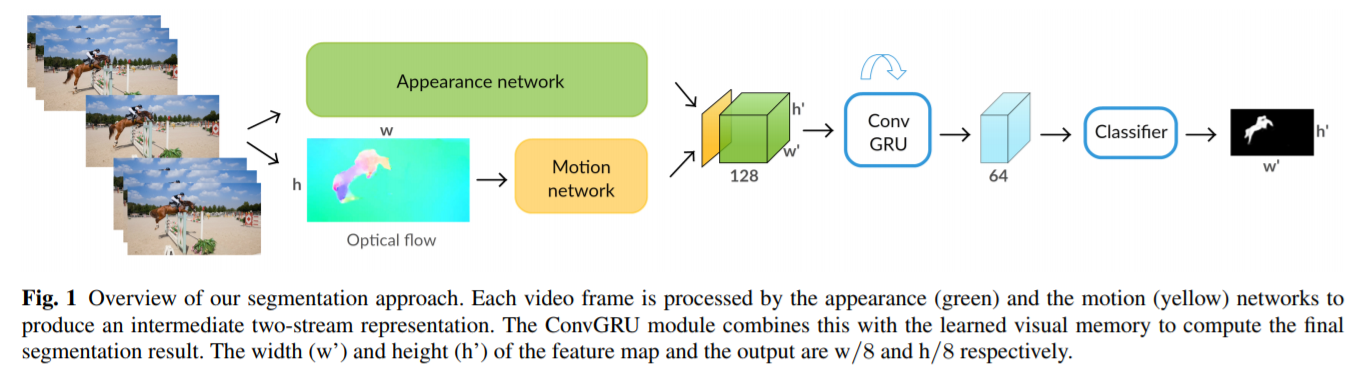
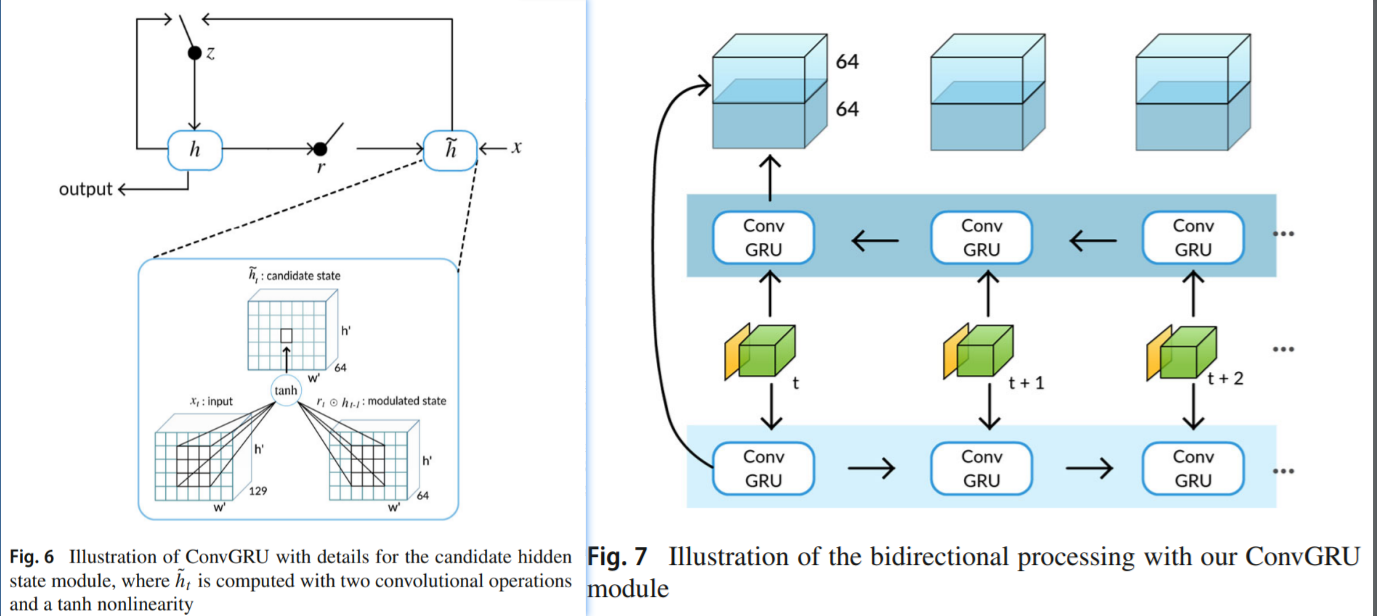
在本文中,我们采用了基于卷积GRU(ConvGRU)的视觉记忆模块,并表明它是一种有效的方法来编码视频中对象的时空演变以进行分割。为了充分受益于视频序列中的所有帧,我们双向应用递归模型
Motion部分网络结构:
ConvGRU Visual Memory Module: RNN记忆部分
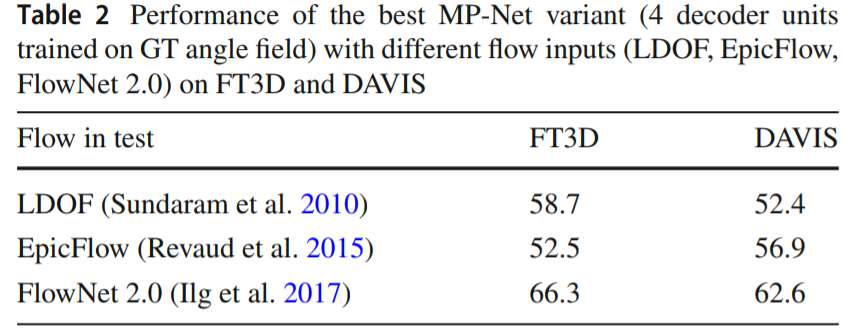
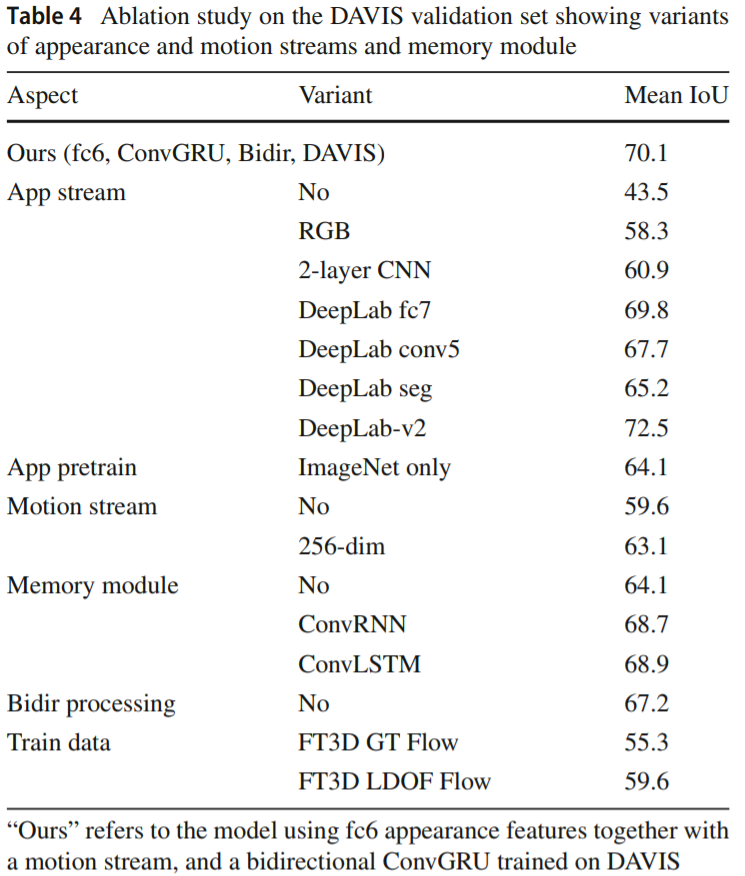
实验结果: DAVIS 无监督第三,比较有意思的一个结果是光流输入不同的结果考察和Ablation study
Learning Unsupervised Video Object Segmentation through Visual Attention
我们首次定量验证了人类观察者视觉注意行为的高度一致性,并发现在动态,任务驱动的观察过程中人类注意力和明确的主要对象判断之间存在很强的相关性。我们将无监督的视频目标分割分为两个子任务:
- 时空域中的UVOS驱动的动态视觉注意预测(DVAP)
- 空间域中的注意引导的对象分割(AGOS) 这么做很像人看东西 首先看到感兴趣部分 然后细化观察
本文算法有三个主要优点:
- 模块化培训,无需使用昂贵的视频分割注释,而是使用更实惠的动态固定数据来训练初始视频注意模块,并使用现有的固定分割配对静态/图像数据
说的不就是COCO?来训练后续分割模块; - 通过多源学习进行全面的前景理解;
- 来自生物学和可评估的注意力的额外可解释性。
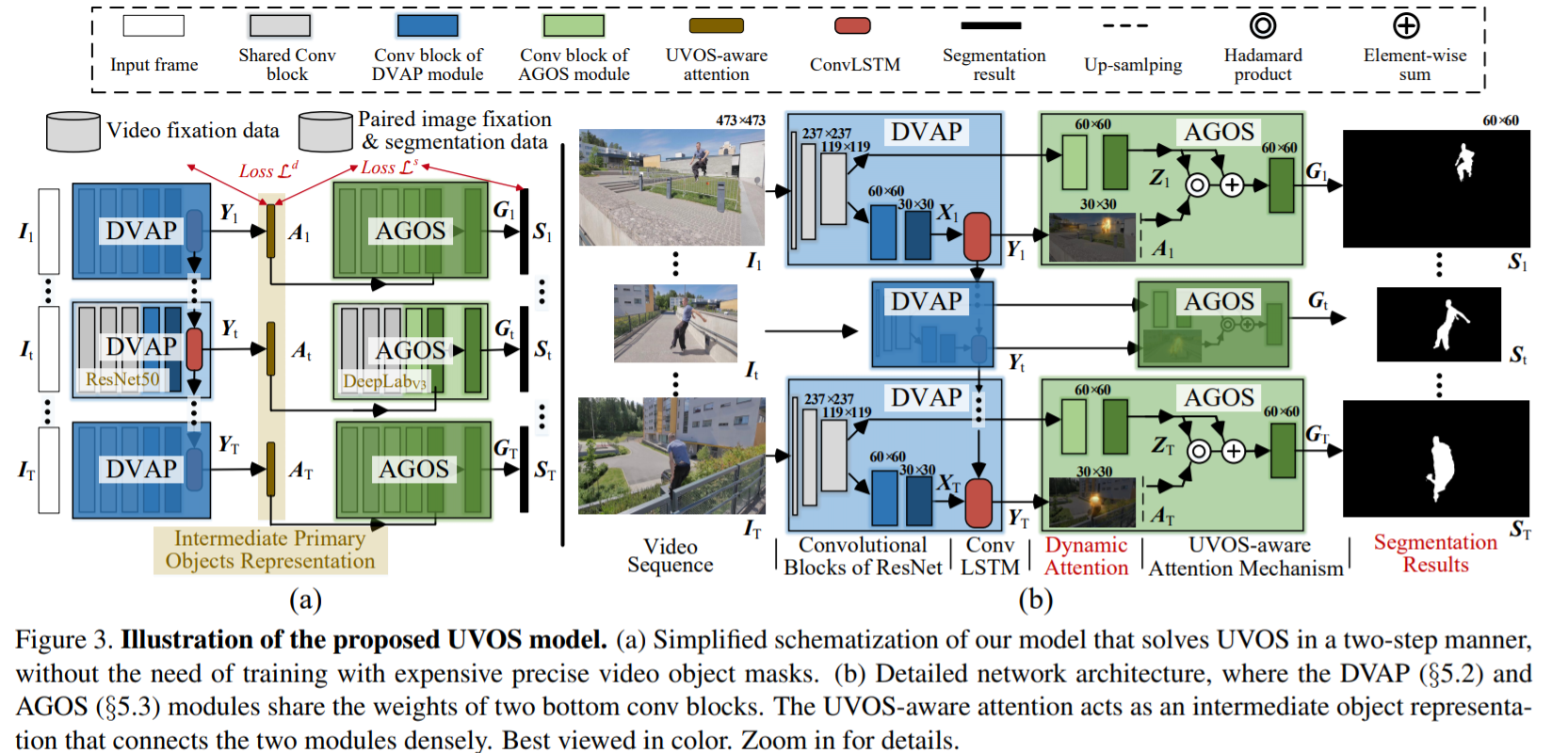
这里的注意力预测用到了salient object segmentation显著性分割
- DVAP用到了CNN-convLSTM结构
- AGOS用到了FCN结构
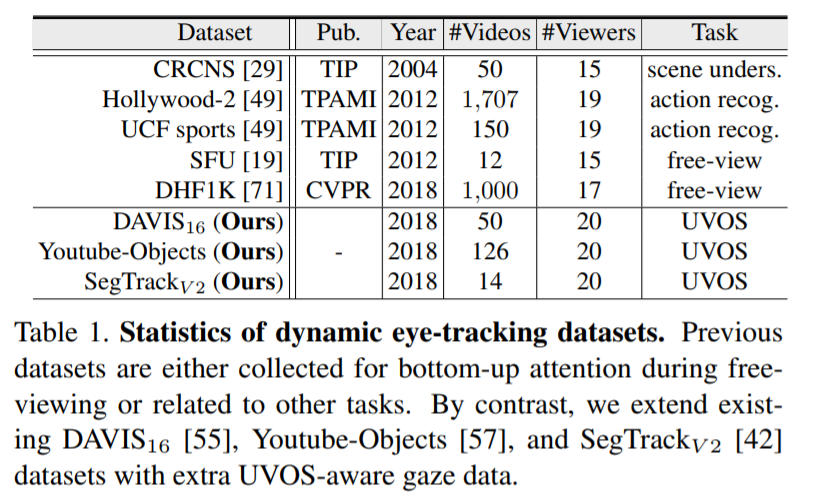
关于视觉凝视的数据集
实验结果

Video Object Segmentation using Teacher-Student Adaptation in a Human Robot Interaction (HRI) Setting
MotAdapt提出了一种新颖的师生学习范例,用于教授机器人周围环境。双流动作和外观“教师”网络提供伪标签以适应外观“学生”网络。学生网络能够在其他场景中对新学习的对象进行分段,无论它们是静态还是动态。
我们还引入了精心设计的数据集,该数据集用于提出的HRI设置,表示为(I)nteractive(V)ideo(O)bject(S)egmentation。我们的IVOS数据集包含不同对象和操作任务的教学视频。我们提出的自适应方法优于DAVIS和FBMS的状态,分别为F-measure的6.8%和1.2%。它在IVOS数据集的baseline上有所改善,mIoU为46.1%和25.9%
在预测期间,我们的方法可以学习分割对象而无需手动分段注释。教师模型是一个完整的卷积网络,结合了运动和外观,表示为“运动+外观”。适应的学生模型是单流外观完全卷积网络,表示为“外观”。在教师网络中组合运动和外观允许创建用于适应学生网络的伪标签
教师网络:RESNET+空洞卷积 使用伪标签的师生适应 Teacher-Student Adaptation using Pseudo-labels:我们的方法提供了两种不同的适应方法,基于离散或连续标签进行调整
- 当使用离散标签时,它基于来自教师网络输出中的自信像素的伪标签。这种方法提供了高精度,但是以调整确定这些自信像素的参数为代价
- 连续标签适应。该方法减少了对任何超参数调整的需要,但降低了降低精度的成本
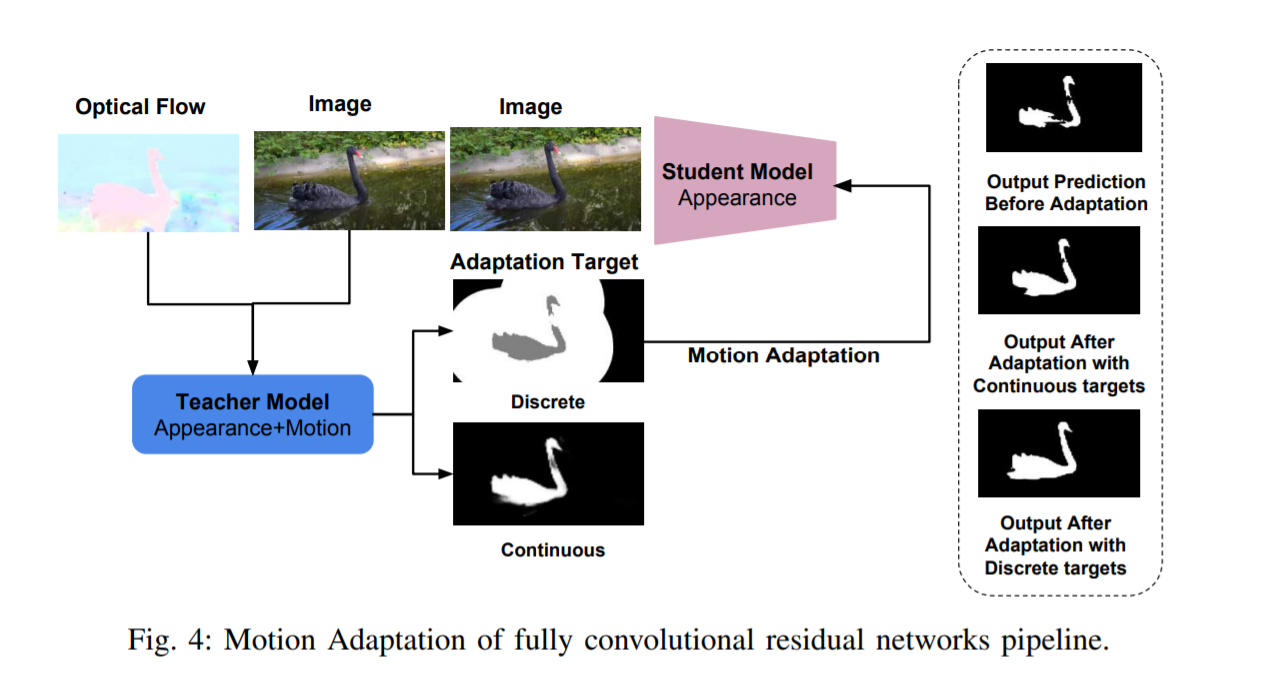
离散和连续的算法区别:
- 连续:直接把teacher输出给student算
- 离散:给出认为比较确定的正样本像素标为1,确定的背景像素标为0,可以看出会有两个超参数阈值,多出来的参数需要调,所以更麻烦

本篇文章还提出了一个数据集