MPI Sintel Flow Dataset
Evaluation
- EPE : End-to-end point error is defined as the Euclidean distance between these two:
- Another common error measure is the interpolation error.通过使用光流来外推(“扭曲”)当前帧来实现插值误差。然后将外推图像与视频的真实下一帧进行比较。插值误差可以很好地衡量光流用于视频编码的程度,而端到端点误差可以很好地衡量它如何用于计算机视觉任务,例如运动形状和喜欢。
DATASET
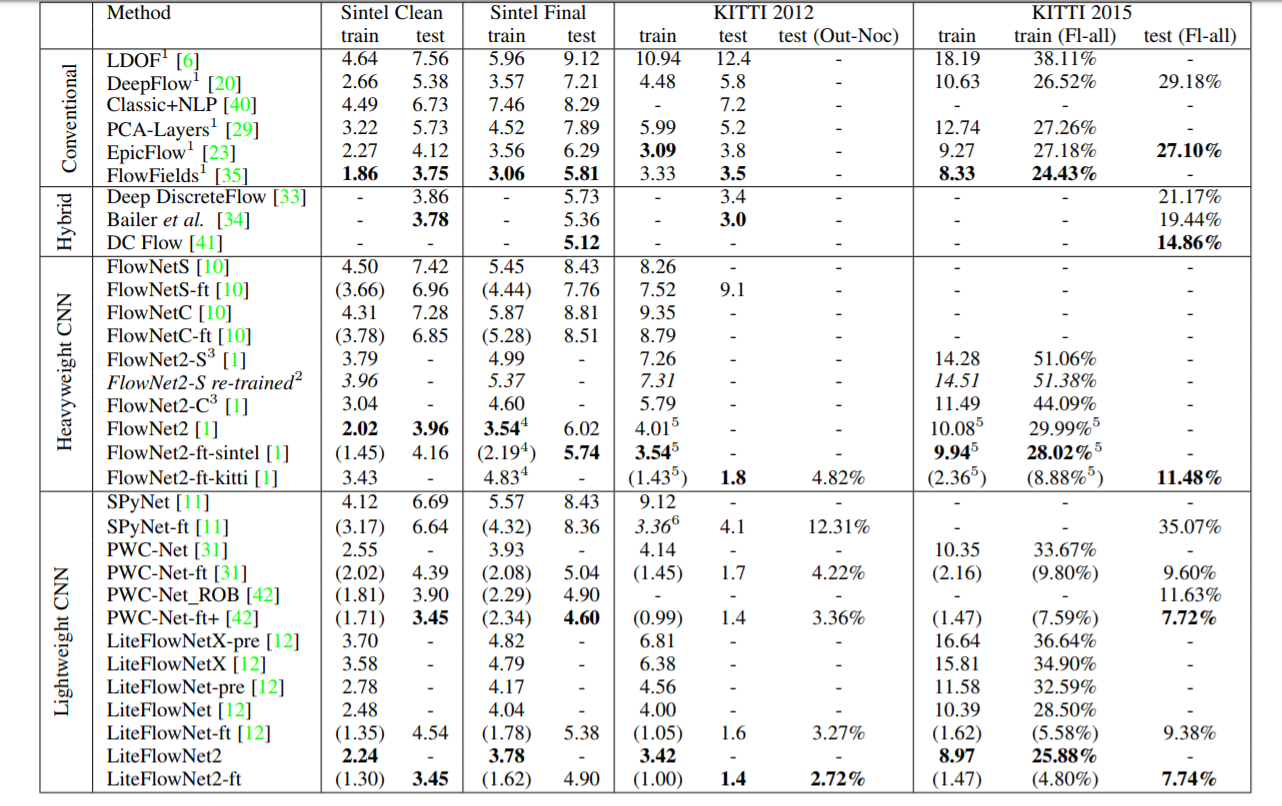
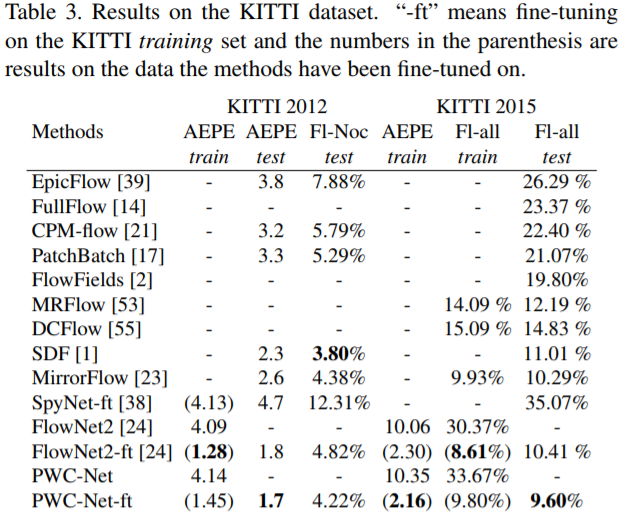
Method
史前方法 flownet && flownet2
PWC
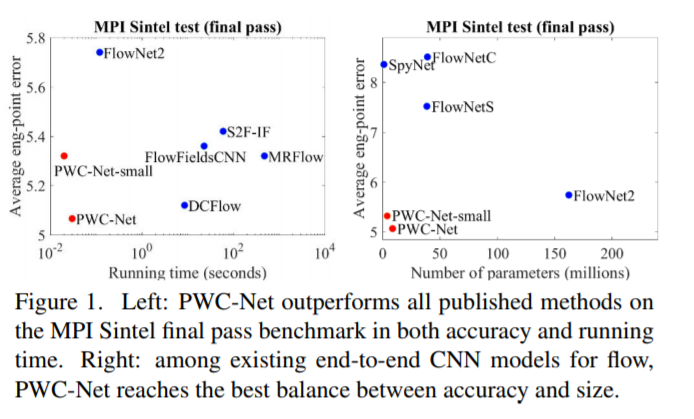
PWC-Net的设计遵循简单和完善的原则:金字塔形加工,翘曲和cost volume的使用。 投射在可学习的特征金字塔中,PWC-Net使用当前的光流估计来扭曲第二图像的CNN特征。然后,它使用第一图像的扭曲特征和特征来构造 cost volume,其由CNN处理以估计光流。
算法
首先,由于原始图像是阴影和光照变化的变体,我们用可学习的特征金字塔替换固定图像金字塔。 其次,我们将传统方法中的变形操作作为我们网络中的一层来估计大的运动。 第三,由于成本量是光流比原始图像更具辨别力的表示,我们的网络有一层构建cost,然后由CNN层处理以估计流量。变形和cost volumn层没有可学习的参数并且减小了模型尺寸。最后,传统方法的一个常见做法是使用上下文信息对光流进行后处理,例如中值滤波和双边滤波。因此,PWC-Net使用上下文网络来利用上下文信息来细化光流。与能量最小化相比,翘曲,成本体积和CNN层在计算上是轻的
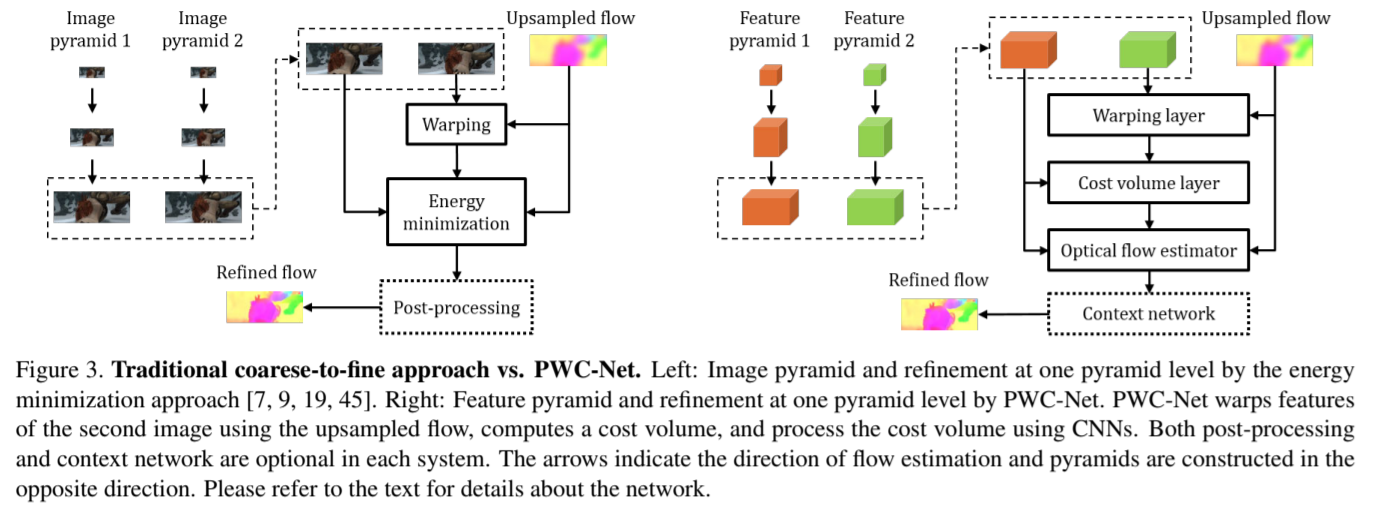
Feature pyramid extractor金字塔特征提取器,卷积层下采样
Warping layer扭曲层,我们使用来自第L+ 1级的×2上采样流将第二图像的特征扭曲到第一图像,双线性插值补偿几何损失
Cost volume layer Cost volume用于存储在下一个帧中将像素与其对应像素相关联的匹配成本
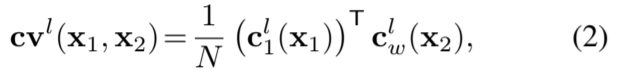
Optical flow estimator多层卷积网络,输入是成本量,第一张图像的特征和上采样光流,其输出是第l列的流量wl
Context network 传统的流方法通常使用上下文信息来对流进行后处理。因此,我们采用称为上下文网络的子网络来有效地扩大所需金字塔等级处的每个输出单元的感受域大小。它从光流估计器获取第二个最后一层的估计流量和特征,并输出精细流量
我们使用FlowN中提出的相同的多尺度训练损失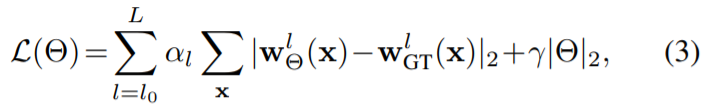 finetune的时候改为
finetune的时候改为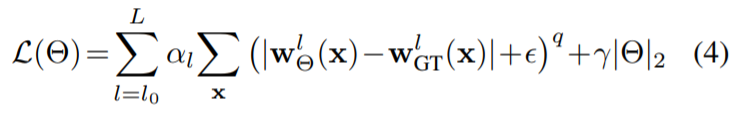
实验结果

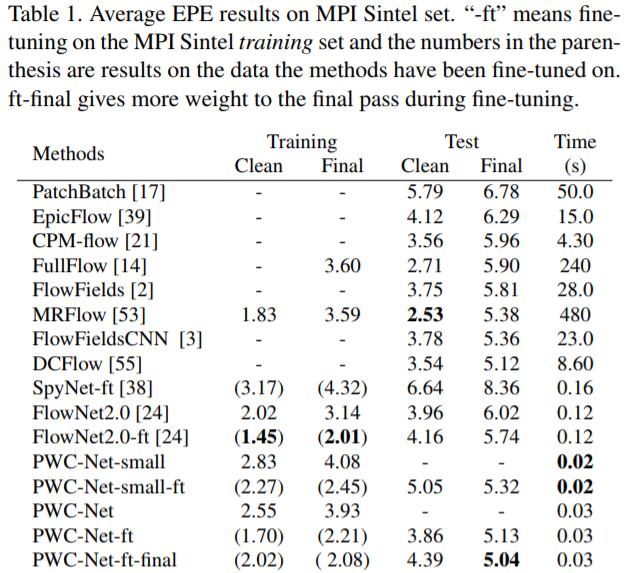

SelFlow: Self-Supervised Learning of Optical Flow
缺少大量的真实数据的标注,一般情况下光流的训练方法都是在合成的标签的数据集上先训练,然后在小的标注训练集上微调,一个有希望的方向是开发受益于未标记数据的无监督光流学习方法,基本思想是根据估计的光流将目标图像变换到参考图像,然后使用光度损失最小化参考图像和变换目标图像之间的差异 本文的方法是根据可靠的无遮挡的像素得到的光流,对于遮挡的光流进行指导。

使用相同的网络架构训练两个CNN(NOC-Model和OCC-Model)。前者侧重于非遮挡像素的精确流量估计,后者学习预测所有像素的光流。我们从NOC模型中提取可靠的非遮挡流量估计,以指导那些被遮挡像素的OCC模型的学习。测试时只需要OCC模型。


Occlusion Estimation 对于双帧光流估计,我们可以交换两个图像作为输入以产生前向和后向流,然后可以基于前向后向一致性先前生成遮挡图为了在我们的三帧设置下工作,我们建议利用相邻的五帧图像作为输入
对于前向后向一致性检查,当前向流和反向前向流之间的不匹配太大时,我们将一个像素视为被遮挡。以Ot→t +1为例,我们可以先计算反向正向流,如下所示

每当像素违反以下约束时,该像素被视为被遮挡

Occlusion Hallucination在我们的自我监督训练期间,我们通过随机噪声扰动局部区域来产生幻觉。在新生成的目标图像中,与噪声区域对应的像素自动被遮挡。有许多方法可以生成这种遮挡,naive的方法是用长方形区域,但是实际情况下很少用这种遮挡,所以使用超像素使用超像素有两个主要优点。首先,超像素的形状通常是随机的,超像素边缘通常是对象边界的一部分。这与现实案例一致,使噪声图像更加逼真。我们可以选择位于不同位置的几个超像素来覆盖更多的遮挡情况。其次,每个超像素内的像素通常属于同一对象或具有相似的流场。
Photometric Loss 设置为

为了训练我们的OCC模型来估计包含像素的光流,我们为那些合成的被遮挡像素定义了一个自我监督损失Loss,首先,我们计算一个自我监督掩模M来表示这些像素

Loss为

本算法也可以应用于2帧光流和多帧光流
光流效果

A Lightweight 1 && 2
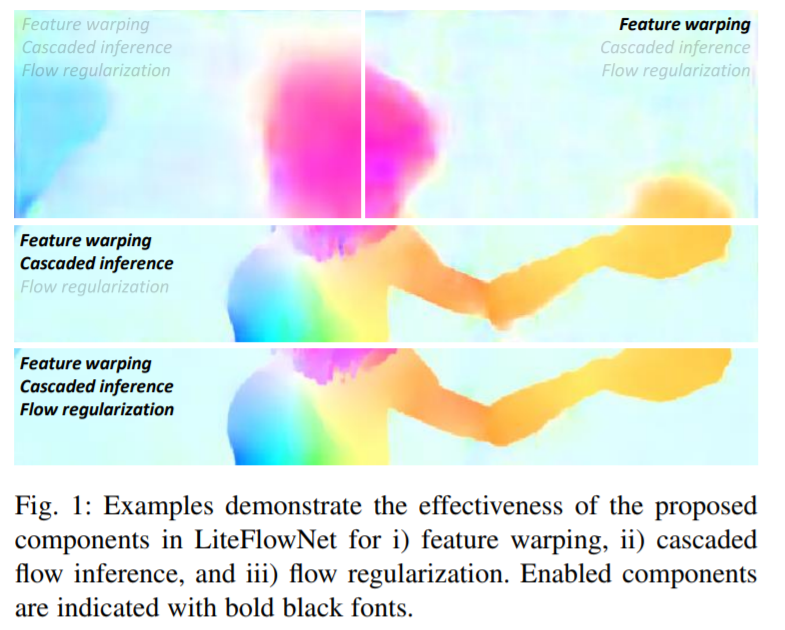
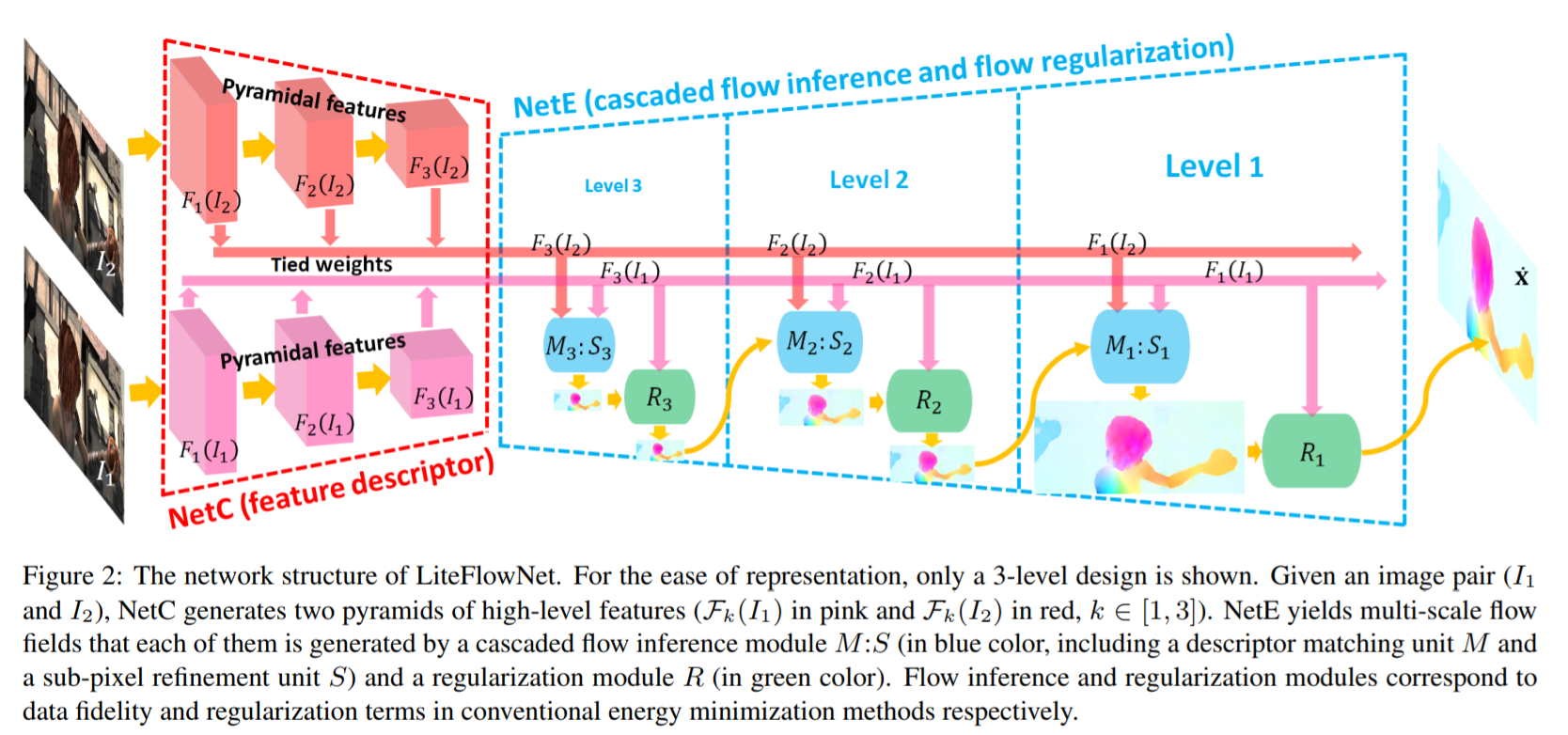
LiteFlowNet: A Lightweight Convolutional Neural Network for Optical Flow Estimation第一代改版,第一代创新点:1.使得前向传播预测光流更为效率通过在每一个金字塔层添加一个串联网络。2.添加一个novel flow regularization layer来改善异常值和模糊边界的情况,这个层是通过使用feature-driven local convolution来实现的。3.我们的网络拥有一个有效的金字塔特征提取结构,并采用feature warping而不是像FlowNet2中所做的image warping。 有三种方法来减少cost volume过程中的计算负担
- perform short-range matching at every pyramid level instead of longrange matching at a single level
- reduce feature-space distance between F1 and F2 by warping F2 towards F1 using our proposed f-warp through flow estimate x from previous level.
- perform matching only at the sampled positions in the pyramid levels of high-spatial resolution. The sparse cost volume is interpolated in the spatial dimension to fill the missed matching costs for the unsampled positions.
高阶特征的逐像素的匹配会产生粗略的光流,紧接着对于此粗略的光流进行一次refinement,可以把此粗略光流的精度提升至sub-pixel级的精度
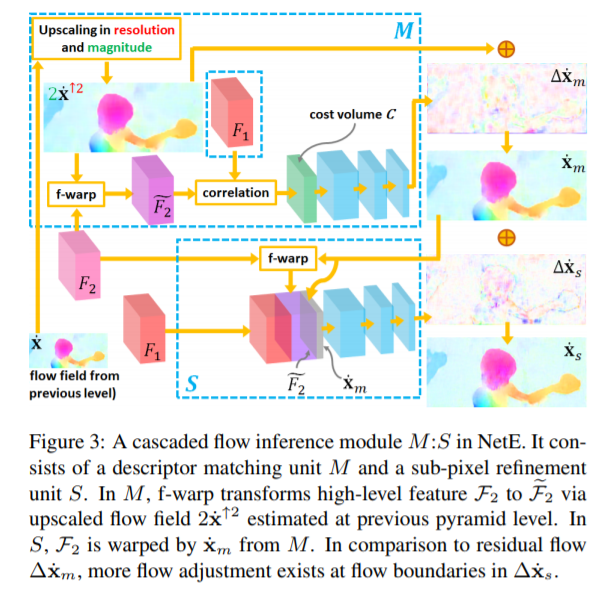
只使用Cascaded flow inference,会造成边界模糊,以及在光流场中不希望见到的artifacts,为此,使用a feature-driven local convolution(f-lcon)技术来对cascaded flow inference阶段产生的光流场进行正则。相比于local convolution,feature-driven local convolution的通用性更好。体现在不仅为feature map的每个位置都使用了一个不同的过滤器,而且为每个flow patch自适应地构造了过滤器
f-lcon 滤波器的作用为平滑光流场,假如光流场在一个小块中是平滑的那么这个滤波器就相当于中值滤波器,同时不能过度平滑图像的边缘
第二代:我们的LiteFlowNet2在Sintel和KITTI基准测试中的性能优于FlowNet2,同时占用空间小25.3倍,运行速度快3.1倍。我们通过以下改进了LiteFlowNet的网络架构
- at level 3 to that at level 2 时间长准确率提升低 去除掉
- 补偿上述改进损失 加两层网络
- 给level2加一个a simplified flow inference:在流动推理中的最后一层和正则化中的f-lcon层之前移除所有层,并通过分别从流层推理中的最后一层之前的层以及第3层的正则化层中的上采样特征替换所移除的层
就是改动了网络,具体不如看源码
实验结果又提升了一些